The AI revolution is here, but enterprise adoption is messy.
While developers are eager to integrate GPT-4, Claude, and other LLMs into their applications, IT teams are asking the hard questions: How do we control access? How do we ensure security? How do we monitor usage across teams?
Brighteye is the answer - an open-source LLM gateway that sits between your applications and AI providers, giving you the enterprise-grade controls you need without slowing down innovation.
The Enterprise AI Dilemma
Picture this: Your development team wants to add AI features to your customer support platform. Marketing wants to use LLMs for content generation. Your data science team is experimenting with different models for analysis.
Each team needs different access levels, security controls, and usage limits. But most LLM providers offer basic API keys with minimal management features. You’re left with:
- 🔑 API keys scattered across teams with no central control
- 🔒 Security gaps where sensitive data might leak into prompts
- 📊 Zero visibility into who’s using what, when, and how much
- 🔄 Vendor lock-in making it hard to switch between providers
- ⚡ No rate limiting leading to potential service abuse
Sound familiar? You’re not alone.
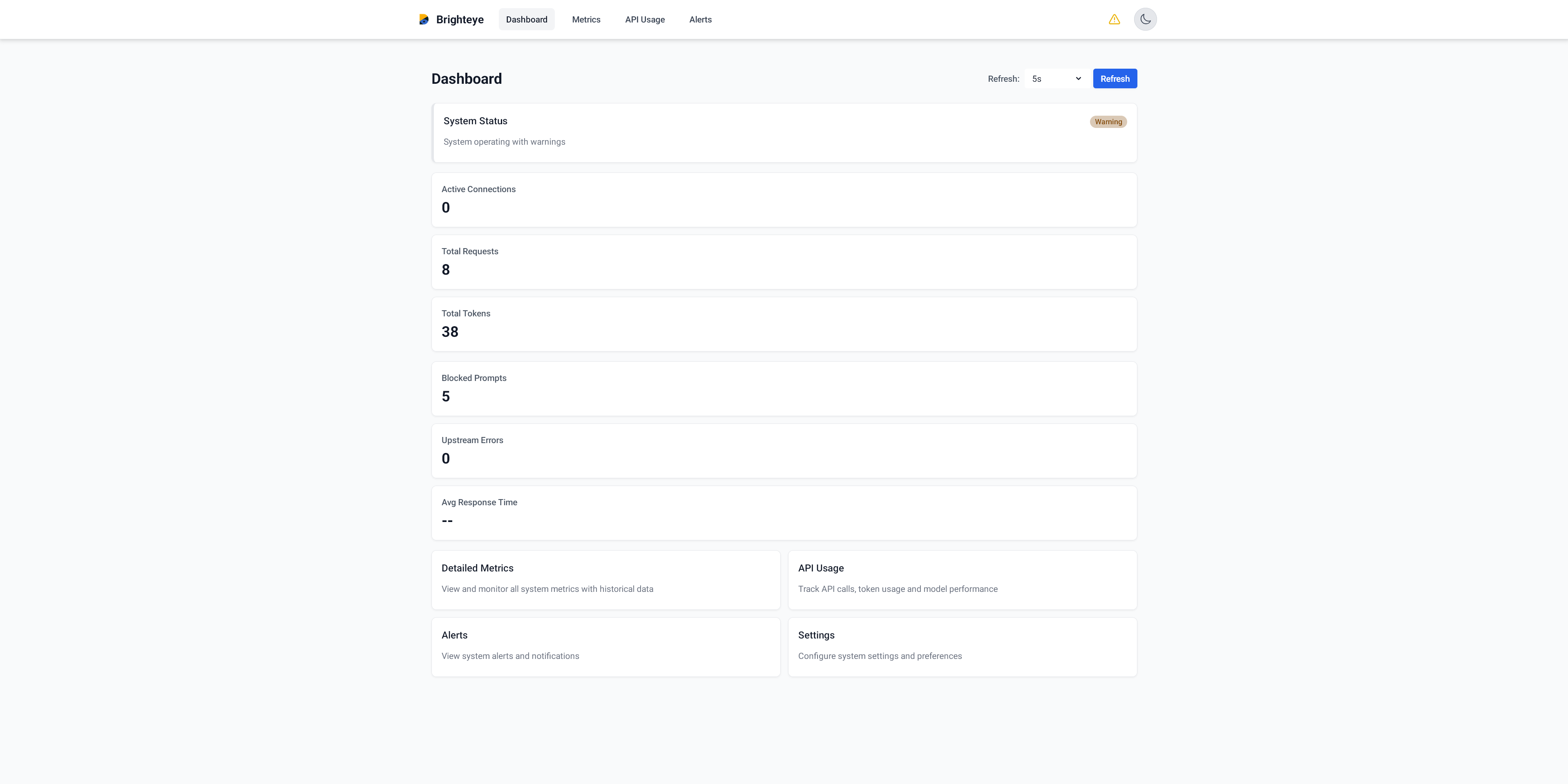
Brighteye's main dashboard provides real-time insights into your LLM usage
How Brighteye Solves Real Enterprise Problems
🛡️ Security That Actually Works
Instead of hoping developers follow security guidelines, Brighteye enforces them automatically:
# Example: Prevent PII leakage
promptFilter:
blocklist:
- "harmful content"
- "inappropriate request"
regex:
- "(?i)password"
- "(?i)secret"
maxPromptLength: 4000
Real-world impact: Brighteye automatically blocks prompts containing sensitive patterns, preventing potential data leaks to external LLM providers.
🔐 Centralized Access Control
Organize teams with proper permissions and quotas:
keyGroups:
- name: "development"
apiKeys:
- key: "dev-key-123"
label: "Development Team"
permissions:
- provider: "openai"
models: ["gpt-3.5-turbo", "gpt-4"]
rateLimit:
rpm: 50
burst: 5
tokenQuota:
daily: 5000
Each team gets their own API keys with specific model access and usage limits.
⚡ Smart Rate Limiting
Prevent abuse and ensure fair usage across teams:
- RPM (Requests Per Minute): Control request frequency
- Burst Limits: Allow temporary spikes while maintaining overall limits
- Token Quotas: Daily token usage limits per team
📊 Comprehensive Monitoring
Brighteye provides detailed metrics through Prometheus:
- Request patterns by team, model, and provider
- Usage statistics with token consumption tracking
- Performance metrics including response times and error rates
- Security events like blocked prompts and quota violations
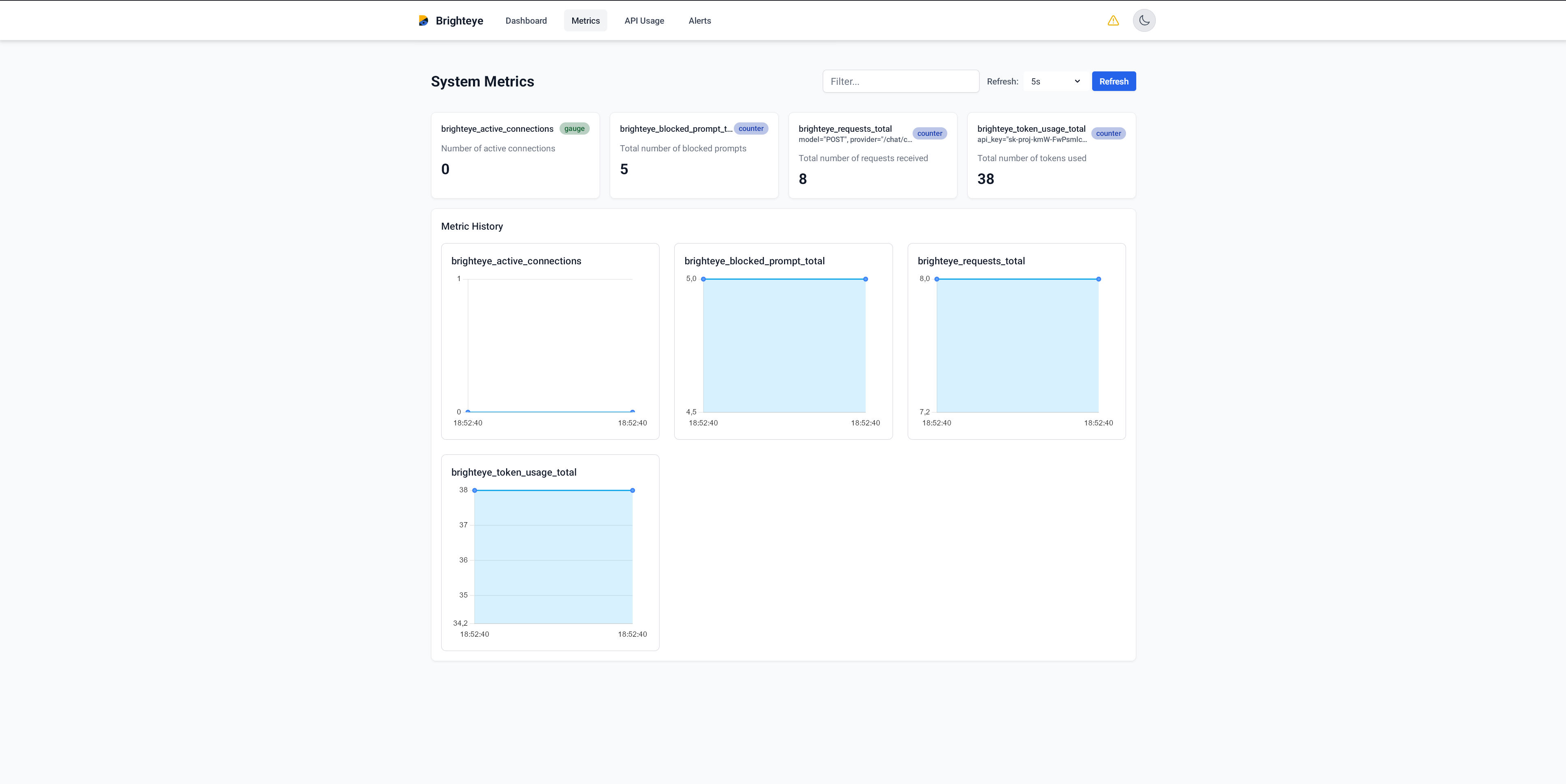
Detailed analytics showing usage patterns across teams and models
🔄 Provider Flexibility Without Vendor Lock-in
Switch between OpenAI, Anthropic, or other providers without changing your application code:
# Same API call, different provider
curl -X POST http://localhost:8080/chat/completions?provider=openai
curl -X POST http://localhost:8080/chat/completions?provider=anthropic
The Architecture That Makes It Work
Brighteye’s design is elegantly simple:
[Your App] → [Brighteye Proxy] → [LLM Provider]
↓
[Metrics & Logs]
- Your application sends requests to Brighteye instead of directly to the LLM provider
- Brighteye validates the request against security policies, quotas, and rate limits
- If approved, the request is forwarded to the specified provider
- Response is returned to your application with full observability
This approach provides centralized control without requiring changes to your existing applications.
Configuration Deep Dive
Entry Points Configuration
entryPoints:
web:
address: 8080 # Main API endpoint
metrics:
address: 9090 # Prometheus metrics endpoint
Provider Setup
providers:
default: "openai"
services:
- name: "openai"
base_url: "https://api.openai.com/v1"
models:
- name: "gpt-3.5-turbo"
- name: "gpt-4"
- name: "gpt-4-turbo"
allowedPaths:
- "/chat/completions"
- "/completions"
- name: "anthropic"
base_url: "https://api.anthropic.com/v1"
models:
- name: "claude-3-haiku"
- name: "claude-3-sonnet"
- name: "claude-3-opus"
allowedPaths:
- "/messages"
Team-Based Access Control
keyGroups:
- name: "production"
apiKeys:
- key: "prod-key-789"
label: "Production API"
permissions:
- provider: "openai"
models: ["gpt-3.5-turbo", "gpt-4", "gpt-4-turbo"]
- provider: "anthropic"
models: ["claude-3-haiku", "claude-3-sonnet", "claude-3-opus"]
rateLimit:
rpm: 200
burst: 20
tokenQuota:
daily: 20000
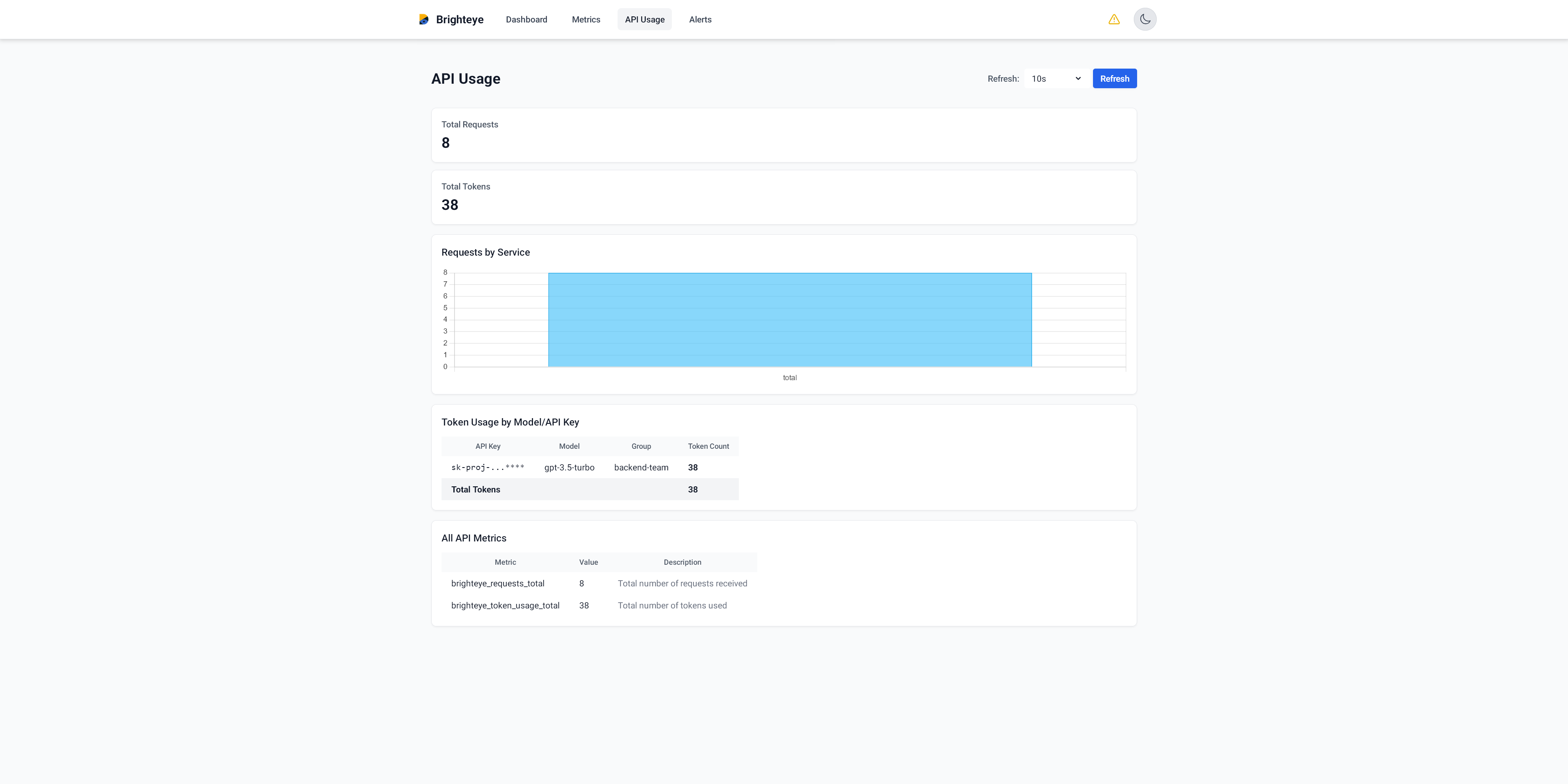
Detailed analytics showing usage patterns across teams and models
Getting Started in 5 Minutes
Step 1: Clone and Configure
# Clone the repository
git clone https://github.com/mehmetymw/brighteye
cd brighteye
# Edit configuration
cp brighteye.yaml.example brighteye.yaml
# Update API keys and settings
Step 2: Run with Docker
# Build and run
docker build -t brighteye .
docker run -d \
--name brighteye \
-p 8080:8080 -p 9090:9090 \
-v $(pwd)/brighteye.yaml:/app/brighteye.yaml \
brighteye:latest
Step 3: Make Your First Request
curl -X POST http://localhost:8080/chat/completions?provider=openai \
-H "Authorization: Bearer dev-key-123" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "user", "content": "Explain quantum computing in simple terms"}
]
}'
Step 4: Monitor Usage
# Check metrics
curl http://localhost:9090/metrics
# View specific metrics
curl http://localhost:9090/metrics | grep brighteye_requests_total
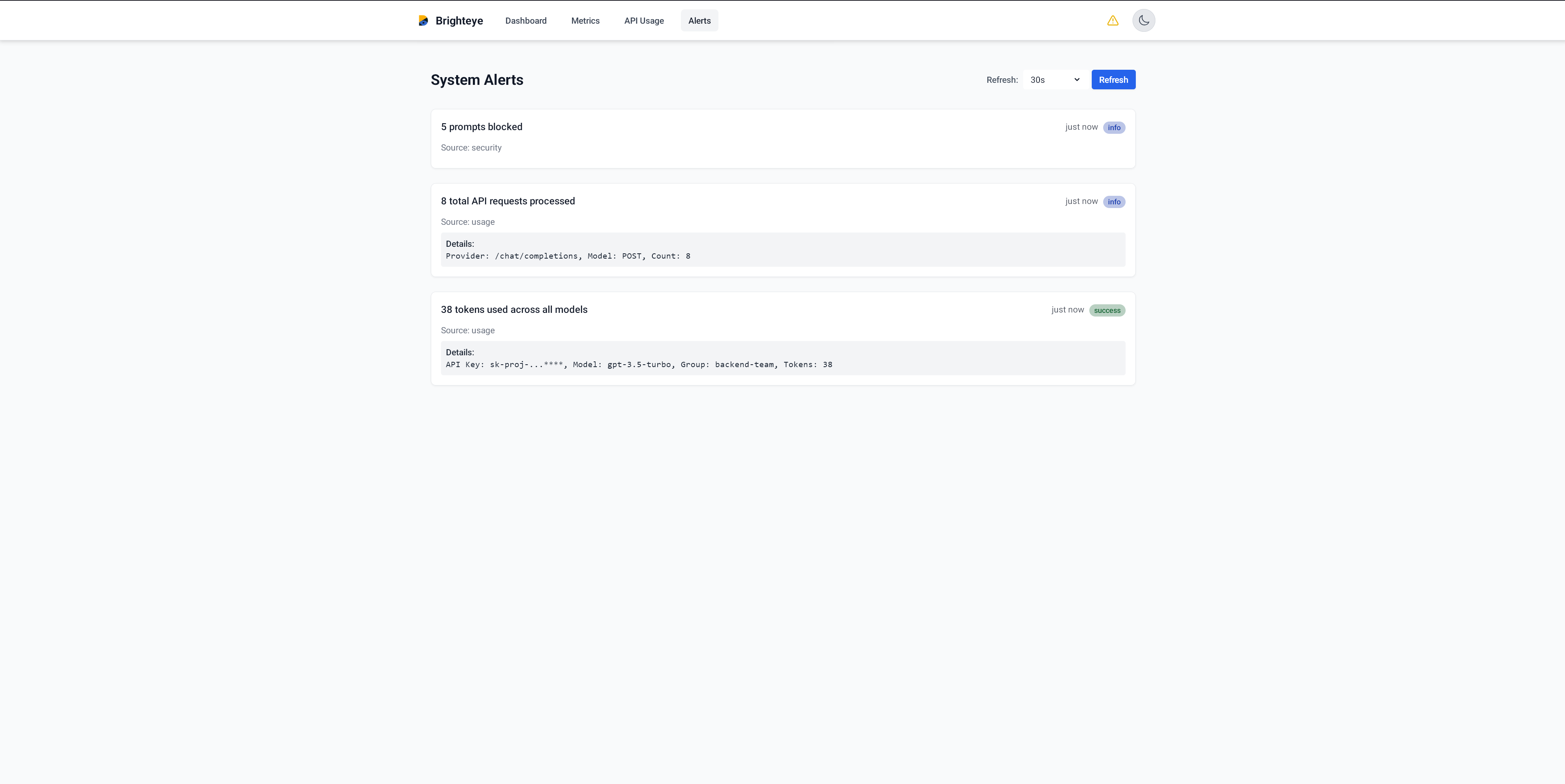
Detailed API Usages of teams and models
Key Features in Detail
🔒 Security Features
- Prompt Filtering: Block sensitive content using blocklists and regex patterns
- Content Length Limits: Prevent excessively long prompts
- API Key Management: Centralized key management with labels and permissions
- Audit Logging: Complete request/response logging for compliance
⚡ Performance Features
- Low Latency: Minimal proxy overhead (<5ms)
- Rate Limiting: Configurable per-team limits
- Burst Handling: Allow temporary spikes while maintaining overall limits
- Health Checks: Built-in monitoring endpoints
📊 Monitoring Features
- Prometheus Metrics: 15+ built-in metrics
- Request Tracking: Detailed usage statistics
- Error Monitoring: Track failures and response codes
- Token Usage: Monitor token consumption per team
🔄 Multi-Provider Support
- OpenAI Integration: Full support for GPT models
- Anthropic Integration: Claude model support
- Extensible Architecture: Easy to add new providers
- Provider Switching: Runtime provider selection
Real-World Use Cases
Enterprise Development Teams
- Separate API keys for dev, staging, and production
- Different rate limits and quotas per environment
- Centralized monitoring across all environments
Multi-Team Organizations
- Marketing team: Limited to content generation models
- Engineering team: Full access to all models
- Research team: Higher quotas for experimentation
Compliance-Heavy Industries
- Automatic PII detection and blocking
- Complete audit trails for all requests
- Configurable content filtering rules
Monitoring and Observability
Available Metrics
# Request metrics
brighteye_requests_total{provider="openai", model="gpt-4", status="200"}
brighteye_request_duration_seconds{provider="openai"}
# Usage metrics
brighteye_tokens_used_total{provider="openai", model="gpt-4", type="input"}
brighteye_daily_active_keys_total
# Error metrics
brighteye_errors_total{provider="openai", error_type="rate_limit"}
brighteye_blocked_requests_total{reason="prompt_filter"}
Grafana Integration
# Example Grafana dashboard query
sum(rate(brighteye_requests_total[5m])) by (provider, model)
What’s Coming Next
The Brighteye roadmap focuses on enterprise adoption:
Q1 2025
- 🔐 Advanced Authentication: JWT and SSO integration
- 📊 Enhanced UI Dashboard: Web-based monitoring interface
- 🔌 Plugin System: Extensible architecture for custom integrations
Q2 2025
- ⚡ Request Caching: Intelligent response caching
- 📡 Webhook Integration: Real-time notifications and alerts
- 🧪 A/B Testing: Compare model performance
Q3 2025
- ⚖️ Load Balancing: Multi-instance provider load balancing
- 🔄 Circuit Breakers: Automatic failover and recovery
- 📬 Request Queuing: Queue management for high-traffic scenarios
Contributing
Brighteye is open source and welcomes contributions:
- GitHub: github.com/mehmetymw/brighteye
- Issues: Report bugs and request features
- Pull Requests: Contribute code improvements
- Documentation: Help improve guides and examples
# Contributing workflow
git clone https://github.com/mehmetymw/brighteye
cd brighteye
git checkout -b feature/your-feature
# Make changes
git commit -m "Add your feature"
git push origin feature/your-feature
# Create pull request
License
Brighteye is released under the MIT License, making it free for both personal and commercial use.